Git developed by Linus Torvalds is the most widely used source control system. It empowers developers by managing different versions of source files and it provides lot of features to aid in development. Stash may be my favorite feature of all. Below summarizes how git stores data.
The .git hidden folder
Once we initialize git for a folder, a hidden folder gets generated. This hidden .git folder has everything git needs to manage the folders and files from here on and to support all git features.
Contents of .git folder
The .git has different folders like hooks, info, refs and files like Head, config to store different forms of information including the actual data. These folders and files also holds information about branches, current branch, commits etc. Below are the main ones,
| Folder/File | Purpose |
| objects/ | Contains all the content (blobs and trees) and metadata (commits and tags) of the repository |
| refs/ | Holds references to commits, such as branches and tags |
| config | Configuration file for the Git repository |
| HEAD | Points to the currently checked-out branch or commit |
| index | Staging area or index that tracks changes before committing |
| logs/ | Contains logs of various Git actions |
| ignore or .gitignore | A file specifying files and patterns to be ignored by Git |
Look inside .git\objects folder
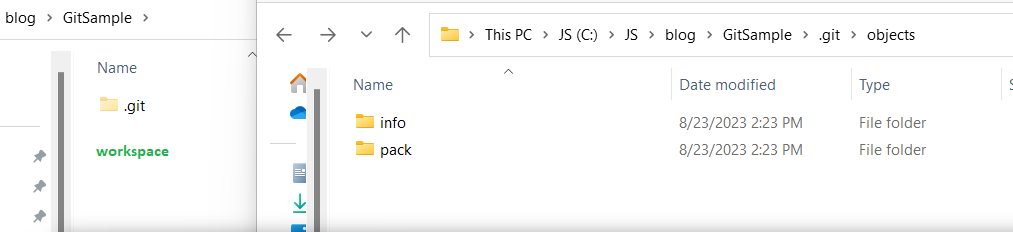
Objects is probably the most important folder since it actually stores the data of the files git manages. It also has metadata information about commits. Lets initialize git on an empty folder named “GitSample” as below. At this stage, objects folder will be empty (except info and pack folder which we can ignore for this discussion).
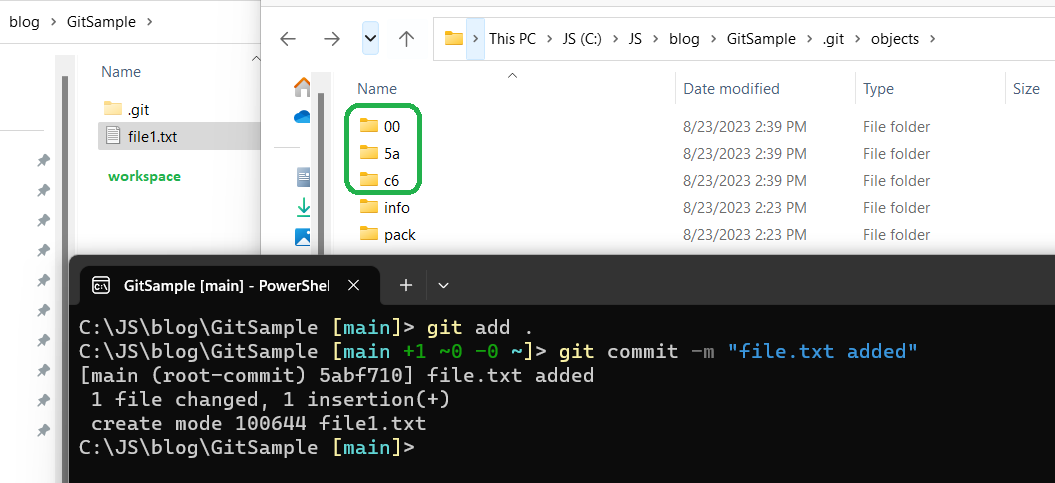
After above, I have a added a text file called “file1.txt” with a short content and committed. As in below image, 3 new folders are created inside the .git\objects folder.
Hashing and folder structure
Git uses SHA-1 hash to store information. Say git want to store string “abc” in its system. Git will create a SHA-1 hash of the string “abc” and stores that information inside a folder with its first two characters. This hashing helps git to be very efficient, since hash of “abc” will be same in any condition and any change say “abcd” will result in a totally different hash. Thus duplicate contents like two files with same data needs only one hash data file.
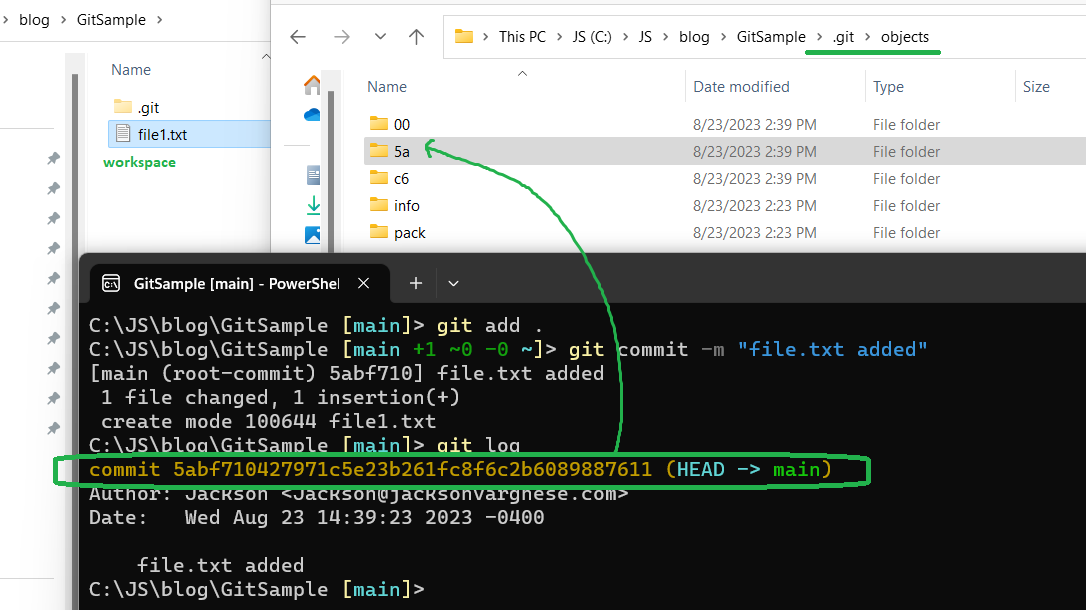
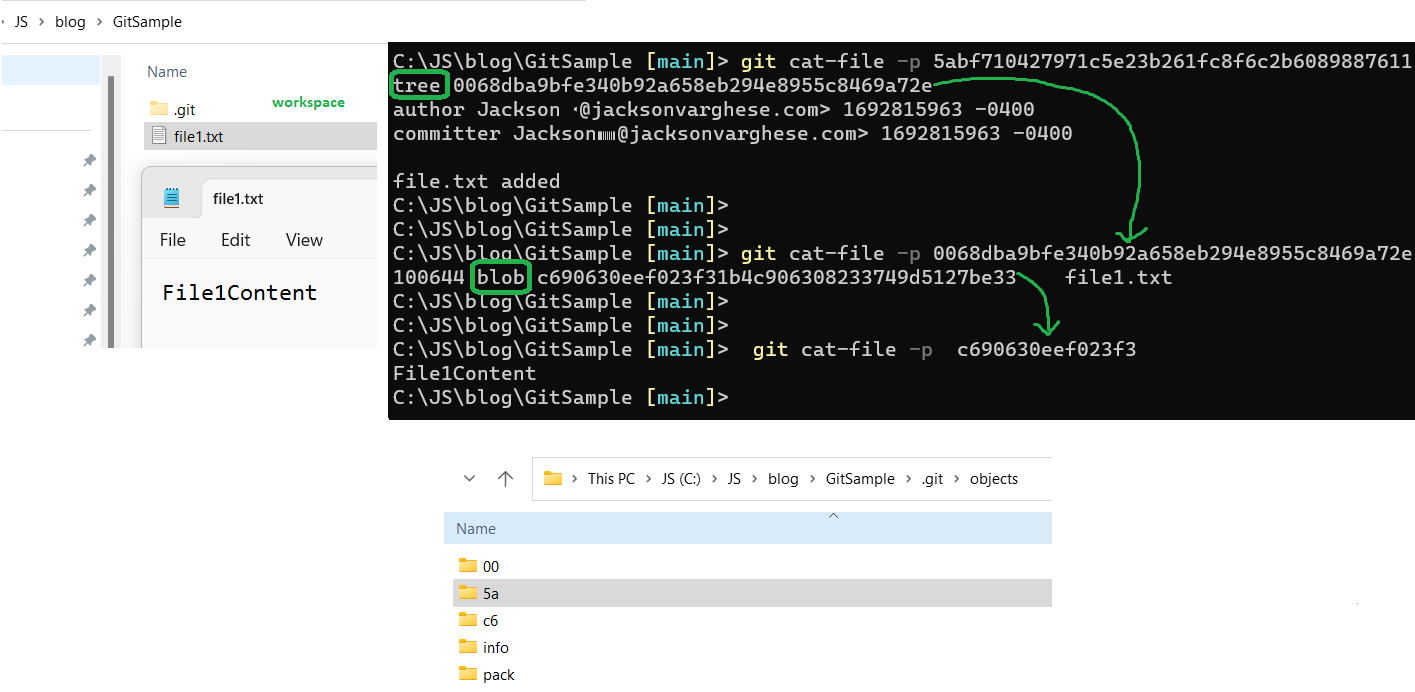
When we run git log, we get the the Id of the only commit we did. In the objects folder git stores information about commits as well. Once git hash’s the information about commit (5abf710427971c5e23b261fc8f6c2b6089887611), its creates a folder with first two characters (5a) and stores it.
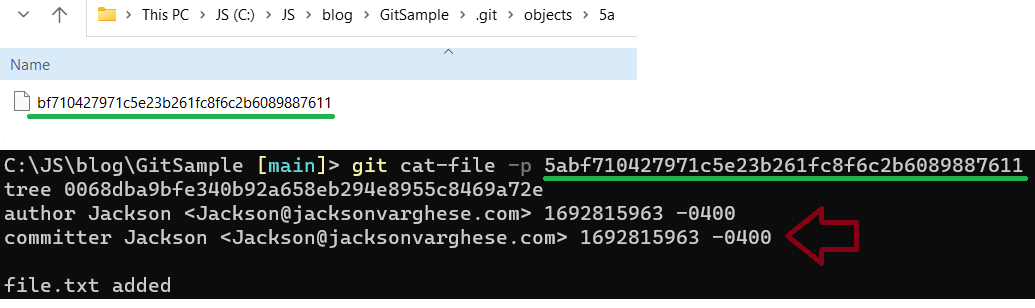
Look inside Commit file
Using the low level command git cat-file -p “SHA1-Hash” we can see the contents of any hashed files inside objects folder. Looking inside the “~.git\objects\5a\bf710427971c5e23b261fc8f6c2b6089887611” we can see data for Tree, author, committer, commit message and optionally parent commit id when applicable.
What is a tree and blob in git
Tree refers to folders and blob refers to file contents (actual data) in git. Trees can be composed of more trees (folder inside folder) and/or the list of blobs (files). It only has the metadata of the actual file(s) which carries the contents just like a folder in windows explorer.
Running cat-file with the tree’s hash will reveal the actual file’s metadata (file1.txt). The tree file 0068dba9bfe340b92a658eb294e8955c8469a72e will store what all items (more folders/files) stored inside but the actual data in itself is stored in blobs.
(The cat-file command also supports first few characters of the hash, thus we don’t have to enter the full hash to execute it).
We can run the blob’s hash c690630eef023f31b4c to get the content of the actual text file we committed. Cat-file the blob’s hash will retrieve the content “File1Content” stored in file1.txt. Thus Content of File1.txt is stored inside c690630eef023f31b4c. If we had two files (file1.txt and file2.txt) with same content, git can thus use the same blob to represent both the text files. Its important to not the blob is the content and tree usually have mapping to blobs.
How Everything is connected
Using the SHA-1 hashes, git manages to effectively store all the data it needs to function. A git Branch is connected to a Commit which is connected to Trees/Blobs forming a hierarchy of data structure. This hierarchy enable git to time travel and show you different versions of past. When we have multiple commits made, git can create the full hierarchy of files and folders based on the current branch (pointed commit) by joining and mapping parent commit details.
Current Branch –> Current Commit –> Trees(s) –> Blob(s)